Why Log Returns
A reader recently asked an important question, one which often puzzles those new to quantitative finance (especially those coming from technical analysis, which relies upon price pattern analysis):
Why use the logarithm of returns, rather than price or raw returns?
The answer is several fold, each of whose individual importance varies by problem domain.
Begin by defining a return: 


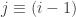
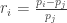
Benefit of using returns, versus prices, is normalization: measuring all variables in a comparable metric, thus enabling evaluation of analytic relationships amongst two or more variables despite originating from price series of unequal values. This is a requirement for many multidimensional statistical analysis and machine learning techniques. For example, interpreting an equity covariance matrix is made sane when the variables are both measured in percentage.
Several benefits of using log returns, both theoretic and algorithmic.
First, log-normality: if we assume that prices are distributed log normally (which, in practice, may or may not be true for any given price series), then 
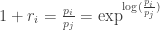
This is handy given much of classic statistics presumes normality.
Second, approximate raw-log equality: when returns are very small (common for trades with short holding durations), the following approximation ensures they are close in value to raw returns:
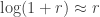
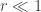
Third, time-additivity: consider an ordered sequence of 
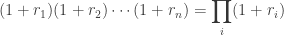
This formula is fairly unpleasant, as probability theory reminds us the product of normally-distributed variables is not normal. Instead, the sum of normally-distributed variables is normal (important technicality: only when all variables are uncorrelated), which is useful when we recall the following logarithmic identity:
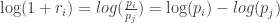
Thus, compounding returns are normally distributed. Finally, this identity leads us to a pleasant algorithmic benefit; a simple formula for calculating compound returns:
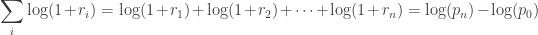
Thus, the compound return over n periods is merely the difference in log between initial and final periods. In terms of algorithmic complexity, this simplification reduces O(n) multiplications to O(1) additions. This is a huge win for moderate to large n. Further, this sum is useful for cases in which returns diverge from normal, as the central limit theorem reminds us that the sample average of this sum will converge to normality (presuming finite first and second moments).
Fourth, mathematical ease: from calculus, we are reminded (ignoring the constant of integration):

This identity is tremendously useful, as much of financial mathematics is built upon continuous time stochastic processes which rely heavily upon integration and differentiation.
Fifth, numerical stability: addition of small numbers is numerically safe, while multiplying small numbers is not as it is subject to arithmetic underflow. For many interesting problems, this is a serious potential problem. To solve this, either the algorithm must be modified to be numerically robust or it can be transformed into a numerically safe summation via logs.
As suggested by John Hall, there are downsides to using log returns. Here are two recent papers to consider (along with their references):
Trackbacks
- Finanzas 101: Calculos con Retornos « Quantitative Finance Club
- Why Minimize Negative Log Likelihood? « Quantivity
- Why log returns? « mathbabe
- Geometric Efficient Frontier « Systematic Investor
- Pathetic Model Using VIX To Predict S&P 500, Part 1 | Curated Alpha
- Links 30 Mar « Pink Iguana
- franziss | Pearltrees
- Pair Trading Model « ickyatcity
- Learning Algorithmic Trading | Bordering Insanity
- Misleading Elvish Statistics | Chen's blog
- Why log returns ? |
- Why Use Log Returns? | Châteaux de Bah
- Desempenho e Risco de Estratégias de Investimento | Blog do Dr. Nickel
- Thursday Roundup, 10/30/2014 | Homines Economici
- Log Matters - Quantivity - Market Remarks
- A Return by Any Another Name… | Crumbs
- Numeracy for Traders - Lesson 2 - Exponentiation, polynomials, logarithms and the power of compound returns
- การคำนวณ Rate Return จากราคาหุ้นย้อนหลัง 10 ปีด้วย Python – I'm Aoddy.
- Rebalansavimas, kodėl? - Dar vienas blogas apie asmeninius finansus..
- Copy Copy Copy Learn Time Series Analysis in Python - Introduction (1/4) dup dup dup - TradeWithScience
- Backtesting a Trading Strategy with Pandas and Python - Learn Python with Rune
- การคำนวณ Rate Return จากราคาหุ้นย้อนหลัง 10 ปีด้วย Python | I'm Aoddy.
- Cryptocurrency Analysis with Python — Log Returns – coin24
- Let's make GARCH more flexible with Normalizing Flows - Sarem Seitz
- Return Distribution in Financial Markets – What are they and how to calculate them – NOTES AND STUFF
- Wealth Management | Pearltrees

I’m glad you posted this. It certainly was something I struggled with for a long time. This is one of those things that I never learned in school or on the CFA curriculum and if I didn’t start reading academic papers I never would have figured out.
In my own study, I was convinced most by the explanation in Meucci’s Risk and Asset Allocation book. There are hints of what he says in what you say. Basically, his argument is that you should take some invariants and then map them to expected market prices. Since you should be concerned about how these invariants move forward into time and how they can be combined into market prices, the properties of the invariants are more important than the properties of the final market prices (arithmetic returns are easy to aggregate for 1 point in time, but geometric returns are better to aggregate through time). Also, as you note, there is an easy formula to convert one to the other.
I was a bit tripped up in his analysis b/c if the geometric returns follow some garch or regime-switching process, then they aren’t IID. However, the log returns of these variables can still be projected in each period following these processes and then mapped to market prices for use in optimization. Meucci has a good short paper on why you shouldn’t use the projection of log returns in optimization on ssrn.
Good point to highlight the downsides. Updating post now to include links to several relevant papers.
With respect to the paper on high frequency trading, the variable that is modelled as iid is the cross-sectional volatility of principal components. There is absolutely no relationship between this independence and the returns of stocks in the original dimension. It is intuitive to model on a short term horizon the shocks that dislocate the relative relationships of principal components as iid events. This characteristic makes the Euclidean distance a good tool to measure aggregate change in these dislocations over a period of time H. Under this scenario, returns in the original dimension can very well show autoregressive behavior, and by no means there is an assumption of independence between them. I think the main point of the paper lies here: the real model is on the cross-sectional vol of principal components, and not in the returns themselves. Hope this helps. P.-
Regarding the paper links: There is no perfect objective metric. Log returns assumes that investors hate variance per se, whereas in fact investors hate drawdowns. Investors also hate some integral of drawdowns convolved with a convex function of time. Unless they subscribe to some philosophy, e.g. buy-and-hold-and-never-let-go, that has taught them otherwise.
@human: agreed, thanks for your comment; more formally, investors appear to hate negative semi-variance and express that temporal preference non-linearly. I am working on an Asset Allocation post that introduces more formality of both ideas; would be interested to get your ideas / comments on that, after it is posted.
Are you a former geologist? I was using the word “quasimetric” rather than “semivariance”
Did you read Danny Kahneman’s paper on remembered utility? That gave me some ideas on what kind of function to convolve the downside against.
It might be even more complicated than downsides — maybe brief upsides vs spiky upsides vs long-and-steady affects how investors take the downside. I’m reading The Big Short right now. It’s incredible how Michael Burry’s investors lampooned him, even when he was RIGHT, calling the biggest short of the last decade with surgical precision. http://books.google.com/books?id=eParwQ0YdrcC&printsec=frontcover&dq=the+big+short&hl=en&src=bmrr&ei=vQ9VTpCDN8K_tgfDl_CPAg&sa=X&oi=book_result&ct=book-thumbnail&resnum=1&ved=0CEIQ6wEwAA#v=onepage&q=his%20investors&f=false
Sure – you have my email now – so beep at me when you’ve finished it.
Another answer to the question of the title is http://www.portfolioprobe.com/2010/10/04/a-tale-of-two-returns/
Well,with due respect, I opine that the real answer to the ‘why ln(x), instead of x’ question is more elegant than the articlesuggests:
‘X’ amount of profit is a quantity in a 10-digit space,which gives a distorted view of natural quantities. One has to take the natural logarithm of a naturally occured quantity to bring it down to the undistorted /real scale. This is why it is called ‘Natural’ Logarithm. Hence, we takke the natural logiartihm of the returns to apply summation and substraction operations on them.
This is also why , the ln() of the returns has a normal distribution..This is also why, linear interpolation works on the ln() of the returns.
Hello, let me ask something. Do you know if i can use excess returns with logs? Moreover, if i decide to use log how can derive the difference with risk- free rate?
Do really mean $\log(p_n) – \log(p_0)$?
Why dont you write $\log(r_n) – \log(r_0)$ instead?
@Michael: expression is correct, due to identity:
I’m a writer from Stonefield, Great Britain just forwarded this onto a coworker who was running some research on this. And she actually ordered me lunch just because I came across it for her… lol. So allow me to reword this…. Thanks for the meal… But yeah, thanx for spending some time to talk about this issue here on your blog.
At last, after surfing https://quantivity.wordpress.com/2011/02/21/why-log-returns/ for quite some time, I got a site from which I was able to genuinely discover worthwhile facts in regard to the studies and the knowledge that I
want. There need to be more things like this on WordPress
@quantivity: I am a discretionary trader seeking a quantitative edge.
Have a related question and maybe you can provide guidance.
You said:
“… if we assume that prices are distributed log normally (which, in practice, may or may not be true for any given price series)”
“… given much of classic statistics presumes normality”
Question: How material is the “normality assumption” in creating profitable quant models and strategies?
How can one discern when this assumption is realistic (worth working with as a practitioner) and when is it purely for academical reasons?
Allow me to elaborate based on my limited knowledge so far.
It seems that the vast majority of quantitative education is founded on the normality assumption and on the creation of models from historical distributions.
“Risk” seems to be about going (or not going) outside the first/second standard deviation of the Gaussian curve.
As a trader, it almost sounds like this was born in a “buy and hold” world where time works in an investor`s favor.
Also as a trader, I know that outside the first standard deviations is where the best trades are in this volatile world.
On the other hand (from the Gaussian assumption), quant practitioners like Nassim Taleb advocate for non Gaussian ways.
Some highlights below:
“Granted, it has been tinkered with, using such methods as complementary “jumps”, stress testing, regime switching or the elaborate methods known as GARCH, but while they represent a good effort, they fail to address the bell curve’s fundamental flaws.
…
These two models correspond to two mutually exclusive types of randomness: mild or Gaussian on the one hand, and wild, fractal or “scalable power laws” on the other. Measurements that exhibit mild randomness are suitable for treatment by the bell curve or Gaussian models, whereas those that are susceptible to wild randomness can only be expressed accurately using a fractal scale. The good news, especially for practitioners, is that the fractal model is both intuitively and computationally simpler than the Gaussian, which makes us wonder why it was not implemented before.
…
Indeed, this fractal approach can prove to be an extremely robust method to identify a portfolio’s vulnerability to severe risks. Traditional “stress testing” is usually done by selecting an arbitrary number of “worst-case scenarios” from past data. It assumes that whenever one has seen in the past a large move of, say, 10 per cent, one can conclude that a fluctuation of this magnitude would be the worst one can expect for the future. This method forgets that crashes happen without antecedents. Before the crash of 1987, stress testing would not have allowed for a 22 per cent move.
…
Any attempts to refine the tools of modern portfolio theory by relaxing the bell curve assumptions, or by “fudging” and adding the occasional “jumps” will not be sufficient. We live in a world primarily driven by random jumps, and tools designed for random walks address the wrong problem. It would be like tinkering with models of gases in an attempt to characterise them as solids and call them “a good approximation”.
Pasted from the “A focus on the exceptions that prove the rule” article on ft dot com.
Like I said at the beginning I am looking for a quant edge and need a way to navigate through the vast knowledge and avoid assumptions that are incompatible with a practitioner`s reality.
Can you please offer some criteria and/or references that would help me navigate?
Is the Gaussian assumption safe as foundation for profitable models?
How to verify this?
@Nick: As P&L is what matters for trading, epistemological debates have little productive to offer beyond intellectual amusement (and selling books for Taleb). Day-to-day practice of trading is agnostic to these academic debates.
In practice, the single most important concept to understand is the existence and distinction between alpha model and risk model; and use of the correct corresponding quantitative methodology for each.
Many folks unknowingly conflate the two. Avoid that.
To your specific questions:
Q: How material is the “normality assumption” in creating profitable quant models and strategies?
A: Irrelevant for alpha model; if a model makes money (whatever the distribution), trade it. Maybe relevant for risk model, if alpha phenomenon is best described by a non-Gaussian distribution.
Q: How can one discern when this assumption is realistic (worth working with as a practitioner) and when is it purely for academical reasons?
A: Build and then measure: build a risk model, trade over time, and then measure whether you lose more money than you expect. If you are losing more than your model says, then one of your assumptions is wrong.
Q: Vast majority of quantitative education is founded on the normality assumption and on the creation of models from historical distributions.
A: Historical accident. Gaussian distributions (and exponential distributions, more generally) are mathematically convenient, so much of closed-form Q world is built on them. Modern computational finance and ML methods, such as Monte Carlo methods (e.g. particle filters), are mostly agnostic to distribution assumptions.
Q: Is the Gaussian assumption safe as foundation for profitable models?
A: Maybe or maybe not. Models should be built to describe reality. Blind adherence to any unverified mathematical assumption(s) are likely to lead to hardship in trading.
Q: How to verify this?
A: Many diverse statistical techniques exist. QQ-plot is an elementary technique from exploratory analysis which may be applicable.
Q: Can you please offer some criteria and/or references that would help me navigate?
A: Strive to build models that describe reality. Use the best tools at your disposal and make as few unverified assumptions as possible. Continuously check reality to verify it matches your assumptions.
Thank you for this very convincing explanation. A little point came to my mind regarding the sum of small numbers which you mentioned as a pro of log returns. It is certainly right that arithmetic underflow can occur when multiplying small numbers but also the difference of small numbers is subject to numerical problems, cf. for example here: http://en.wikipedia.org/wiki/Loss_of_significance
Reblogged this on Bright.
Reblogged this on cerebralworks.
hi guys i really cant understand much but I hope you guys can explain abit more simpler for me. when calculating return on stock prices normally we use [St+1/St]-1 , but why some of them uses LN[St+1/St] to calculate the return? When should I use either one of them?
A shorter -but requiring more intution- explanation is as follows: Representation of Naturally occuring quantities in decimal scale is skewed .
Taking e, instead of 10 as the base, removes the skew, so that you can use arithmetical operations on these quantities on that base(e).
actually ratios of logarithms are the same, regardless of base. that is ln(x)/ln(y) = log10(x)/log10(y)
Reblogged this on Sile.
hi, I’m struggling calculating share price performance which is defined as ” the first difference of the logs of annual share prices, matched to the month of firms’ fiscal year-end”.
From my understanding I calculated the logs of returns of month of the year-end, which here is my formula: Ln(monthly return index) of month at time t divided by Ln(monthly return index) of month at time t-1 and then subtract 1. However, Im not really confident about my results.
Could anyone here help me to clarify my calculation above?
I would really appreciate your help. Thank you.
Also, don’t forget another reason we use log returns:
Prices are always greater than zero. p>0. Hence, modelling them with geometric stochastic motion is appealing.
dp = p*r*dt+p*b*dW, guarantees p > 0 (if p_0 > 0), and the solution is log-normal prices.
If instead we chose dp = r*dt + b*dW, p can be anywhere on the reals, which isn’t realistic.
There are other choices that guarantee positive definiteness too, and which are perhaps better suited to modelling prices.
> Thus, the compound return over n periods is merely the difference in log between initial
> and final periods. In terms of algorithmic complexity, this simplification reduces O(n)
> multiplications to O(1) additions.
Knowing the initial and final prices makes the compound return easy, O(1), to calculate even for returns too, not only for log returns: (Pn – P0) / P0
From your sentence it seems that only log returns have that property.
Great article and thank you for posting it!
Check this for details
Stackable washer dryer combo, it is advisable
sort through the basic items you’ll must do the laundry
at one point was the actual price of a sale https://math-problem-solver.com/ .
Capabilities, graphs, limits, continuity, derivatives and applications, definite and indefinite integrals.
Thank you for the excellent explanation. One item that I am not clear on is how (1+r) is considered to be equivalent to ‘price’. If fact it is equivalent to a ratio of prices, i.e. pi/pj. How does one arrive at 1+r = price. Isn’t that a necessity to say that log(price) is normally distributed if prices are lognormally distributed?
Though intuitively constant(1 + return) = price, I’m still wondering…
To complex explanation for an average person. It is like teaching Phd to a 5th standard boy.
Kindly explain in easy language, need not to justify with complex equations of stats.
I think the SSRN paper linked belabours the obvious i.e. Jensen’s inequality. The formula they found with Taylor series algebra is just mean of log-normal distribution. No-one should, a priori, expect average of log returns to be same as average of returns.
The key point, as you say, is that operating in log space is computationally useful if we are doing a lot of multiplications. However, it is erroneous to expect statistics computed in log space to be equal to that computed in the original space.
Meucci’s paper is more about mistakes in estimation. Mean-variance utility is either a quadratic on wealth or a consequence of normality of returns. Using log returns to compute utility implies computing utility of log of wealth and it is not the same quantity. The mean-variance utility function is not a linear transformation, therefore the effect on log-space is not “equal”.