Delay Embedding as Regime Signal
Infantino and Itzhaki, in their 2010 thesis Developing High-Frequency Equities Trading Models, utilize a regime switching signal based upon time delay embedding. The intuition underlying this signal and use for regime discovery are unexpectedly interesting.
 Conceptually, their signal is framed within the context of a two-state switching regime (interpreted in the classic technical sense): “momentum” or “mean reversion”. With high frequency equities portfolio data, they informally observe the familiar volatility-regime correlation: high volatility implies momentum (e.g. herd effects), low volatility implies mean reversion (e.g. market making).
Conceptually, their signal is framed within the context of a two-state switching regime (interpreted in the classic technical sense): “momentum” or “mean reversion”. With high frequency equities portfolio data, they informally observe the familiar volatility-regime correlation: high volatility implies momentum (e.g. herd effects), low volatility implies mean reversion (e.g. market making).
In their words: “As the short-term changes in 
How they translate this intuitive volatility-regime correlation into a switching signal is the fun part. They define the difference of 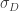
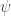
![E_H (t) = \sqrt{\sum\limits_{i=1}^H{[\psi(t - i)]^2}} = \sqrt{\sum\limits_{i=1}^H{[\sigma_D(t - i) - \sigma_D (t - i - 1)]^2}}](https://s0.wp.com/latex.php?latex=E_H+%28t%29+%3D+%5Csqrt%7B%5Csum%5Climits_%7Bi%3D1%7D%5EH%7B%5B%5Cpsi%28t+-+i%29%5D%5E2%7D%7D+%3D+%5Csqrt%7B%5Csum%5Climits_%7Bi%3D1%7D%5EH%7B%5B%5Csigma_D%28t+-+i%29+-+%5Csigma_D+%28t+-+i+-+1%29%5D%5E2%7D%7D+&bg=ffffff&fg=333333&s=0&c=20201002)
This is an interesting starting point, as dynamical systems reminds us that 
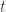
![[ \psi(t - 1), \psi(t - 2), \cdots , \psi(t - H) ]](https://s0.wp.com/latex.php?latex=%5B+%5Cpsi%28t+-+1%29%2C+%5Cpsi%28t+-+2%29%2C+%5Ccdots+%2C+%5Cpsi%28t+-+H%29+%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
 From which they define a binary regime signal
From which they define a binary regime signal 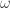

![\omega = [ E_H(t) - E_H(t - 1) ] > 0](https://s0.wp.com/latex.php?latex=%5Comega+%3D+%5B+E_H%28t%29+-+E_H%28t+-+1%29+%5D+%3E+0+&bg=ffffff&fg=333333&s=0&c=20201002)
From which the regime switch is defined: 

This signal is quite interesting when considered within the larger context of several familiar time series analysis traditions:
- Time delay embedding:
- Frequency analysis: delay embedding hints at potential applicability of frequency techniques from signal processing, such as singular spectrum analysis
- Distance metrics:
- Markov chains: interesting questions arise when considering the structure of
Undoubtedly not by accident, the authors conveniently omit their choice of embedding dimension 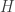

I really find this approach interesting, and I decided to experiment with it a bit. If I achive anything interesting, I will share with you via email. Thanks for the nice blog!
@Aleksey: glad you found it useful; I look forward to hearing if you have similarly positive results. Also, I am drafting a follow-up post describing the cross-sectional volatility metric in more detail, including drilling into the principal component space from which it originates.
I’ve not looked at SSD, though its use by climatologists make it suspect to me (HH-transforms are on my short list of things to look at though). On the other hand, I have been using this “trick” for a while now, with some success. Carol Alexander wrote about it in one of her books, but I kind of thought of it because I wrote a dissertation which talked a bit about the trace formula, and I thought it was an obvious thing to try.
@Scott: Curious to hear what problem domains you have found success with embedding, as it’s a rather general technique.
Re SSD: am I correct in presuming from context that you mean SSA (as first step of SSA is embedding, and climatology research is a frequent user), rather than SSD? I have found the necessity of a priori parameter specification to be an annoyance with applying SSA to trading. While specifying window length is modestly annoying (but not conceptually different than selecting trading clock and time-series sample length), having to evaluate separability for use in X_i groupings gives it an unpleasant whiff of data snooping.
Thank you for initiating this discussion. I have one question. It seems to me that your definition of E_H(t) is different from the paper’s. Or, to be precise, your interpretation of Psi(t-i). You define Psi(t-i)=sigma_D(t) – sigma_D(t-i), when the paper defines it simply as Psi=d sigma_D / dt, which I believe implies Psi(t-i)=sigma_D(t-i) – sigma_D(t-i-1).
Am I missing something here?
@Maxim: correct, thanks for comment. Post updated accordingly.
@quantivity: thank you. Do you have any idea for the reasonable range for H?
Having not optimized on live data, my speculation is optimal H varies dynamically by tick velocity.
The authors state in the paper that the value of H is same as the accumulation parameter they chose before for the regression.