Multi-Asset Market Regimes
An astute reader suggested reproducing the results from a recent article on regime analysis by Kritzman et al., Regime Shifts: Implications for Dynamic Strategies in FAJ (May / June 2012). This is a fun exercise to be conducted over a series of posts, as doing so illustrates several important economic principles and some elegant mathematics.
This post begins by identifying macroeconomic market regimes arising from multi-asset economic activity.
Implicit Momentum Bias
Tadas asked an interesting question in his recent post: Where did all the finance bloggers go? A variety of folks gave thoughtful replies: Josh Brown, Flex Salmon, David Merkel, Scott Bell, the Macro Men, and bunch of anonymous professional traders. Undoubtedly, there is truth in all their observations.
Yet, perhaps there is a common root cause at work, not yet stated: implicit momentum bias.
Volume Clock, Gaps, and GOOG
GOOG unexpectedly disclosed their Q3 earnings early last week, on October 18th. While earnings were marginally interesting, much more amusing was the corresponding hiccup in intraday trading. This event provides an opportunity to dig into TAQ data, view through a HFT lens, and build intuition from some elegant ideas due to Mendelbrot, Clark, and Ané.
Macro Matters and Orthodoxy
Quantivity disliked undergrad macroecon, as it was largely a waste of time: fancy theory lacking compelling evidence, amplified by no consensus within the field à la saltwater versus freshwater.
Few folks could be blamed for such flippancy, as it was mostly harmless throughout the great moderation. In fact, traders took apparent pride in their ignorance of macro—except the global macro guys, obviously. Then, along came a credit crisis.
With that swan, Quantivity concluded it was high time to formulate a systematic macro perspective: a “top down” complement to calibrate “bottom up” quant models. Quantivity brought great humility to this effort, due to both intrinsic complexity and comparatively weaker background in macro.
This post kicks off a few thoughts derived from this effort; hopefully a welcome addition alongside micro analysis. Two caveats are worth noting. First, confirmation bias is particularly dangerous with macro, and thus emphasis is placed on broadly considering diverse viewpoints. Second, these thoughts are posted with a bit of trepidation, given intense desire to avoid politics and policymaking.
Direction of Change Forecasting
Index Return Decomposition prompted several readers to inquire about forecasting the signs of returns, as implied by the 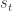
This topic is known as direction-of-change forecasting in the literature. Needless to say, successful prediction of the sign for future returns is quite interesting from a trading perspective. Traditionally, only univariate return series were considered; Anatolyev (2008) is an exception, modeling two or more interrelated markets via dependence ratios. This literature tends to be a bit obtuse, due to commonly unstated stylistic assumptions regarding conditional return dynamics.
Physics, Biology, or Peltzman?
Quantivity is fortunate to be acquainted with numerous folks who have earned consistent returns over multiple decades without significant drawdown. Although they have varying trading strategies, there is a common theme which unifies them: top-down systematic focus on the sociology of market participants.
This focus is not behavioral finance, in search of anomalies driven by cognitive biases divergent from equilibrium (although majority do that too). Rather asking inferential sociological questions, such as: was the market “efficient”, in the Fama sense, during the post-war decades prior to 2000 because people expected it to be (blissfully ignoring a few hiccups); in contrast to how it is commonly understood and formalized, with reverse causality: market is assumed to be efficient, thus people understand it as such.
Similarly, have the past 15 years been “inefficient”, in the bubble and anomaly sense, because cultural faith among investors in such “efficiency” was lost; or, did they lose faith because the market became inefficient? Big difference.
In other words: is finance governed by physics, biology, or Peltzman?
Return Decomposition via Mixing
A variety of techniques exist for estimating parameters of the return decomposition model, previously introduced in Index Return Decomposition. This post considers estimation of an independent mixture model via maximum likelihood (MLE), a workhorse of frequentist statistics and always a nice place to begin.
Recall 
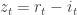
This assumption permits focus on estimating 
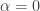
Risk Pragmatics
 Risk is deeply underappreciated.
Risk is deeply underappreciated.
Moreover, it is misunderstood—even by many who have smelled it up close personally via big trading loses on hedged positions. Aaron Brown’s most recent text, Red-Blooded Risk, explains why.
In doing so, it is simultaneously brilliant and flawed. For the former, Brown deserves credit; for the latter, the publisher presumably deserves most of the blame.
Index Return Decomposition
Unmasking a phenomenon 



This technique finds surprisingly often use in quant models.
Ongoing analysis and trading based on proxy hedging, exemplified by series beginning with Proxy / Cross Hedging, suggests potential for an equity decomposition model based on the relationship between returns of a stock 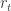
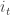
![r_t = s_t \left[ \alpha_t | z_t | + (1 - \alpha_t) \beta | i_t | \right] + \epsilon_t](https://s0.wp.com/latex.php?latex=r_t+%3D+s_t+%5Cleft%5B+%5Calpha_t+%7C+z_t+%7C+%2B+%281+-+%5Calpha_t%29+%5Cbeta+%7C+i_t+%7C+%5Cright%5D+%2B+%5Cepsilon_t+&bg=ffffff&fg=333333&s=0&c=20201002)
To explain this model, let’s build it up from intuition.
Update: Curated Quant Research Feed
Quantivity is pleasantly surprised to discover an increasing number of folks are deriving value from the Curated Quant Research Feed on @Quantivity. Indeed, the combo of daily curated feed with single-source retrospective search has become indispensable for personal research. Towards understanding why, Kedrosky provides nice explanation in his Curation is the New Search is the New Curation post earlier this year:
Head back to curation and watch new algos emerge on top of that next-gen curation again. Think of Twitter as a new stab at curation. Curated sites will re-seed a new generation of algorithmic search sites. In short, curation is the new search.
Indeed, intent of curation here is to maintain high signal-to-noise ratio for a mix of preprint and classics in a highly-specialized literature (i.e. combo of retail