Inquiry: Algebraic Geometry and Topology
Algebraic geometry and topology traditionally focused on fairly pure math considerations. With the rise of high-dimensional machine learning, these fields are increasing being pulled into interesting computational applications such as manifold learning. Algebraic statistics and information geometry offer potential to help bridge these fields with modern statistics, especially time-series and random matrices.
Early evidence suggests potential for significant intellectual cross-fertilization with finance, both mathematical and computational. Geometrically, richer modeling and analysis of latent geometric structure than available from classic linear algebraic decomposition (e.g. PCA, one of the main workhorses of modern 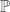
Proxy Conditional Model Selection
Lag Dynamics with Autocopulas investigated autocopulas for underlying and hedge instruments as applied to proxy / cross hedging, concluding the existence of large-magnitude temporal volatility clustering. This is indeed a known stylized fact of financial returns (see Tsay 2010, Chapters 2 and 3).
The classic discrete-time models for capturing such statistical conditionality are ARMA (see Box et. al (1994)) and GARCH (see Engle (1982) and Bollerslev (1986)), for returns and volatility respectively. Yet, therein lies a practical problem faced by hedge analysis: necessity to select a model with optimal parameters and error distribution for underlying and hedge. This post describes and implements such model selection for choosing a model from the universe of standard parameters and non-normal error distributions.
Proxy Hedging and Dependence
When asked to summarize their approach to proxy / cross hedging, senior folks from numerous big banks reduced it to correlation: hedge using an instrument whose correlation is close to -1. This perspective matches the popular practitioner literature, such as recently published text Hedging Market Exposures (Bychuk and Haughey, 2011). Moreover, this perspective is at the heart of much of the research literature, going back to original definition of optimal hedge ratio 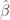

Yet, while indeed true, this wisdom is not terribly helpful in practice for hedging well-known equities, as described in previous posts—as no instrument exists with such high correlation. This motivated revisiting the role of dependence in hedging, uncovering what may perhaps be an interesting result: multi-period asymptotically perfect hedges exist with 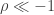
Exploratory Hedge Analysis
Previous posts on empirical quantiles and copulas for proxy / cross hedge illustrate the potential insight from graphical visualization. This post continues the theme, illustrating exploratory data analysis for proxy hedging using classical statistical techniques.
In a world awash with symbolic models, there is ample room for graphical exploratory analysis in finance—as the fine texture of the real world differs from both mathematical formalisms and standard mental models. Indeed, alpha hides in the divergence between model and reality.
Lag Dynamics with Autocopulas
Rakonczai et al. (2010) introduced autocopulas to describe the lag self-dependence structure of a time series. Autocopulas are superior to autocorrelation for the same reasons as copulas are superior to dependence point statistics (e.g. correlation). Readers unfamiliar with copulas are encouraged to review Empirical Copulas and Hedge Basis Risk. Generalizing this notion to arbitrary time series provides an insightful tool for analyzing and visualizing lag dynamics for both individual securities and baskets.
Autocopulas are potentially applicable to all sorts of fun problems in portfolio and risk management, exemplified in this post by considering their applicability to the continuing series on proxy / cross hedging. Further application to generating alpha is fairly straightforward, although left an exercise for readers.
Empirical Copulas and Hedge Basis Risk
The recently introduced proxy hedge model and corresponding empirical proxy quantiles share an implicit dependence on the joint covariation between underlying and proxy hedge. Of particular interest is understanding the dynamics of basis risk under extreme scenarios (both up and down), which are driven by time-varying stochastic joint covariation.
This post quantifies and visualizes such joint covariation and basis risk via copulas, including modeling and empirically fitting both marginal and joint distributions using fat-tailed student-t distributions. Copulas exploit multidimensional sample ranking, and thus are thematically similar to empirical quantiles. This analysis also seeks to exemplify practical use of R for copula analysis.
Empirical Quantiles and Proxy Selection
The previous post on Proxy / Cross Hedging left open an important question: how to choose an appropriate hedge instrument, especially amongst several alternatives. Prior to diving into full exploratory data analysis for proxy hedging (in a forthcoming post), this question is worth careful consideration.
One way to approach this problem is via visualization of empirical quantiles.
Proxy / Cross Hedging
The root challenge of two current equity risk and alpha projects boil down to hedging using non-underlying instruments, known as proxy hedging or cross hedging. This technique is useful for equity shaping trades, as well as an underlying principle for both long / short and statarb:
- Price exposure: neutralize price exposure for stock or basket, possibly leaving behind useful residual (such as dividends or rights)
- Market exposure: neutralize market exposure for a stock or basket, leaving just idiosyncratic exposure
Trading these hedges in practice is more difficult than standard texts suggest (e.g. Hull), as the real world rarely satisfies theory: market incompleteness (challenging risk-neutral 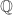
This challenge is explored here via a multi-part series (see Empirical Quantiles and Proxy Selection, Empirical Copulas and Hedge Basis Risk, Lag Dynamics with Autocopulas, Exploratory Hedge Analysis, Proxy Hedging and Dependence, and Proxy Conditional Model Selection), including R code and real data. This first post presents the basic model. The second post will apply this model to a few well-known equities. Readers are encouraged to comment on improvements or alternative techniques on all posts, as this problem is real and remains an open research topic.
You Don’t Have Alpha
Gappy claimed in a thoughtful comment to P-Q Convergence that 
This revisiting led to Cochrane’s recent AFA 2011 Presidential Address on Discount Rates (also available on video). This address is particularly remarkable juxtaposed against French’s 2008 Presidential Address on The Cost of Active Investing which echoed the previous generation of the Chicago school by ardently defending the passive investment grail (imagine having to defend that in the middle of financial meltdown).
Cochrane’s address includes one of the best quotes in the history of modern finance, worthy of reading in its entirety by every serious practitioner (p. 51):
Optimal 10b5-1 Monetization
Increased IPO deal flow is motivating readers to privately inquire about practical algos for compliant 10b5-1 equity / ESO / RSU monetization plans, prompted by the recent three-post theoretical series on Optimal Equity Monetization. This topic is worth exploring for several reasons, prefaced by usual disclaimer of being provided for informational purposes only:
- Microcosm: this topic is a microcosm of trading, as it encapsulates many common problems
- Importance: choice of plan is arguably the single most influential lifetime financial decision
- Real life quant: illustrative example of theory bumping into the vagaries of the financial services industry for retail investors
- Greenfield: literature on this topic is minimal and disconnected from practical reality
- Exotic: illustrative example of arguably the most prevalent retail exotic
This topic will be explored via a new 10b5-1 plan monetization model, compliant with SEC regs and compatible with common practical restrictions imposed by broker counterparties. This model and corresponding background will be presented in parts over several posts, given its non-trivial scope.
