Direction of Change Forecasting
Index Return Decomposition prompted several readers to inquire about forecasting the signs of returns, as implied by the 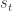
This topic is known as direction-of-change forecasting in the literature. Needless to say, successful prediction of the sign for future returns is quite interesting from a trading perspective. Traditionally, only univariate return series were considered; Anatolyev (2008) is an exception, modeling two or more interrelated markets via dependence ratios. This literature tends to be a bit obtuse, due to commonly unstated stylistic assumptions regarding conditional return dynamics.
The traditional formulation for this topic considers the estimation of the probabilities of returns exceeding an upper or lower threshold 



If 


Estimating these probabilities can be undertaken via several techniques. One approach is to use a logit model, based upon the logistic function:

Where 
An alternative approach is to consider the following functional decomposition for univariate return series:

Where 

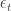

![U_t(c) = \text{Pr} \left[ (\mu_t + \sigma_t \epsilon_t) > c \right] = \text{Pr} \left[ \epsilon_t > \left( \frac{c - \mu_t}{\sigma_t} \right) \right]](https://s0.wp.com/latex.php?latex=U_t%28c%29+%3D+%5Ctext%7BPr%7D+%5Cleft%5B+%28%5Cmu_t+%2B+%5Csigma_t+%5Cepsilon_t%29+%3E+c+%5Cright%5D+%3D+%5Ctext%7BPr%7D+%5Cleft%5B+%5Cepsilon_t+%3E+%5Cleft%28+%5Cfrac%7Bc+-+%5Cmu_t%7D%7B%5Csigma_t%7D+%5Cright%29+%5Cright%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
![D_t(c) = \text{Pr} \left[ (\mu_t + \sigma_t \epsilon_t) < -c \right] = \text{Pr} \left[ \epsilon_t < \left( \frac{-c - \mu_t}{\sigma_t} \right) \right]](https://s0.wp.com/latex.php?latex=D_t%28c%29+%3D+%5Ctext%7BPr%7D+%5Cleft%5B+%28%5Cmu_t+%2B+%5Csigma_t+%5Cepsilon_t%29+%3C+-c+%5Cright%5D+%3D+%5Ctext%7BPr%7D+%5Cleft%5B+%5Cepsilon_t+%3C+%5Cleft%28+%5Cfrac%7B-c+-+%5Cmu_t%7D%7B%5Csigma_t%7D+%5Cright%29+%5Cright%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
With corresponding conditional expectations:
![\text{E} \left[U_t(c) | I_{t-1} \right] = 1 - F_r(c | I_{t-1}) = 1 - F_{\epsilon} \left( \frac{c - \mu_t}{\sigma_t} | I_{t-1} \right)](https://s0.wp.com/latex.php?latex=%5Ctext%7BE%7D+%5Cleft%5BU_t%28c%29+%7C+I_%7Bt-1%7D+%5Cright%5D+%3D+1+-+F_r%28c+%7C+I_%7Bt-1%7D%29+%3D+1+-+F_%7B%5Cepsilon%7D+%5Cleft%28+%5Cfrac%7Bc+-+%5Cmu_t%7D%7B%5Csigma_t%7D+%7C+I_%7Bt-1%7D+%5Cright%29+&bg=ffffff&fg=333333&s=0&c=20201002)
![\text{E} \left[D_t(c) | I_{t-1} \right] = F_r(c | I_{t-1}) = F_{\epsilon} \left( \frac{-c - \mu_t}{\sigma_t} | I_{t-1} \right)](https://s0.wp.com/latex.php?latex=%5Ctext%7BE%7D+%5Cleft%5BD_t%28c%29+%7C+I_%7Bt-1%7D+%5Cright%5D+%3D+F_r%28c+%7C+I_%7Bt-1%7D%29+%3D+F_%7B%5Cepsilon%7D+%5Cleft%28+%5Cfrac%7B-c+-+%5Cmu_t%7D%7B%5Csigma_t%7D+%7C+I_%7Bt-1%7D+%5Cright%29+&bg=ffffff&fg=333333&s=0&c=20201002)
These expectations simplify to the following when 
![\text{E} \left[U_t(c) | I_{t-1} \right] = 1 - F_{\epsilon} \left( \frac{- \mu_t}{\sigma_t} | I_{t-1} \right)](https://s0.wp.com/latex.php?latex=%5Ctext%7BE%7D+%5Cleft%5BU_t%28c%29+%7C+I_%7Bt-1%7D+%5Cright%5D+%3D+1+-+F_%7B%5Cepsilon%7D+%5Cleft%28+%5Cfrac%7B-+%5Cmu_t%7D%7B%5Csigma_t%7D+%7C+I_%7Bt-1%7D+%5Cright%29+&bg=ffffff&fg=333333&s=0&c=20201002)
![\text{E} \left[D_t(c) | I_{t-1} \right] = F_{\epsilon} \left( \frac{- \mu_t}{\sigma_t} | I_{t-1} \right)](https://s0.wp.com/latex.php?latex=%5Ctext%7BE%7D+%5Cleft%5BD_t%28c%29+%7C+I_%7Bt-1%7D+%5Cright%5D+%3D+F_%7B%5Cepsilon%7D+%5Cleft%28+%5Cfrac%7B-+%5Cmu_t%7D%7B%5Csigma_t%7D+%7C+I_%7Bt-1%7D+%5Cright%29+&bg=ffffff&fg=333333&s=0&c=20201002)
These expectations can be evaluated explicitly via calculating the empirical distribution function 


Alternatively, this decomposition suggests one potential formulation for the logit parameters 

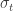

Of course, the non-trivial work is generating forecast estimates for next-step average conditional return 
An alternative way to model the logit parameters 

A survey of estimation techniques may be considered in a subsequent post, depending on reader interest.
One exploratory analysis technique relevant to sign forecasting is visualizing up/down runs, signed difference (i.e. up-down), and corresponding averages for a return series.
returnRuns <- function(r, bound=0, doPlot=TRUE, startAvg=5, avgLen=-1)
{
# Generate up/down runs and average runs for a return series, optionally
# plotting them.
#
# Args:
# r: return series
# bound: symmetric upper and lower bound, aka c
# doPlot: flag indicating whether plots should be generated for runs
# startAvg: Number of average runs which should be excluded for
# eliminating unstable average with few leading observations
# avgLen: number of periods over which to generate average; of -1 for
# entire period
#
# Returns: none
up <- cumsum(ifelse(r > bound, 1, 0))
down <- cumsum(ifelse(r < -bound, 1, 0))
if (doPlot)
{
plot(up, main='Signed Runs: Up & Down', ylim=range(up,down))
lines(down, col='red')
legend("topleft",legend=c("Up","Down"), fill=colors, cex=0.5)
plot(up-down, main="Signed Run Difference (up-down)")
}
if (avgLen == -1)
{
avgUp <- xts(sapply(c(1:length(up)), function(i) {
up[i]/i
}), order.by=index(up))
avgDown <- xts(sapply(c(1:length(down)), function(i) {
down[i]/i
}), order.by=index(up))
} else
{
avgUp <- xts(sapply(c(avgLen:length(up)), function(i) {
start <- i - avgLen + 1
last(cumsum(ifelse(r[start:i] > bound, 1, 0))) / avgLen
}), order.by=index(up[avgLen:length(up)]))
avgDown <- xts(sapply(c(avgLen:length(down)), function(i) {
start <- i - avgLen + 1
last(cumsum(ifelse(r[start:i] < bound, 1, 0))) / avgLen
}), order.by=index(up[avgLen:length(up)]))
}
if (doPlot)
{
n <- length(avgUp)
plot(avgUp[startAvg:n], main=paste("Average Runs: Up & Down (",avgLen," periods)",sep=""), type='l', ylim=range(avgUp,avgDown))
lines(avgDown[startAvg:n], col='red')
legend("topleft",legend=c("Up","Down"), fill=colors, cex=0.5)
}
return (list(up=up, down=down, avgUp=avgUp, avgDown=avgDown))
}
For example, the following plots illustrate CRM run dynamics from 2005 to present. First plot illustrates the running sums for both up and down returns, indicating negative returns are more prevalent:

Second plot illustrates the difference in signed sums, showing time-dynamics for the difference in up and down returns. Not surprising, this difference mirrors the CRM price curve closely:

Third plot illustrates the average probabilities for both up and down, running incrementally over the entire timeframe:

The following are representative papers from the direction-of-change literature, ignoring the early papers focused on evaluating market efficiency (e.g. run tests):
- Forecasting Stock Indices: A Comparison of Classification and Level Estimation Models, by Leunga, Daoukb, and Chenc (2000)
- Financial, Asset Returns, Market Timing, and Volatility Dynamics, by Christoffersen and Diebold (2002)
- Direction-of-Change Forecasts Based on Conditional Variance, Skewness and Kurtosis Dynamics: International Evidence, by Christoffersen et al (2004)
- Are the Directions of Stock Price Changes Predictable? Statistical Theory and Evidence, by Hong and Chung (2003)
- Evaluating Direction-of-change Forecasting: Neurofuzzy Models vs. Neural Networks, by Bekiros and Georgoutsos (2005)
- Modeling Financial Return Dynamics via Decomposition, by Anatolyev and Gospodinov (2007)
- Direction-of-change Forecasts and Trading Strategy Profitability at Intra-Day Horizons, by Deliya (2007)
- Multi-Market Direction-of-Change Modeling Using Dependence Ratios, by Anatolyev (2008)
- Forecasting the Direction of the U.S. Stock Market with Dynamic Binary Probit Models, by Nyberg (2008)
- Direction-of-Change Financial Time Series Forecasting using Bayesian Learning for MLPs, by Skabar (2008)
- A Kernel-Based Technique for Direction-of-Change Financial Time Series Forecasting, by Skabar (2008)
- Optimal Probabilistic and Directional Predictions of Financial Returns, by Thomakos and Wang (2009)
- Directional Prediction of Returns under Asymmetric Loss: Direct and Indirect Approaches, by Anatolyev and Kryzhanovskaya (2009)
- Markets Change Every Day: Evidence from the Memory of Trade Direction, Skouras and Axioglou (2011)
Finally, Kinlay briefly surveyed this topic in two posts on volatility sign prediction.

Excellent post. My research into direction of change forecasting has revolved around simpler, intuitive use of conditional probabilities based on volatility, LIBOR, etc (largely similar to Kinlay’s posts). Looking forward to delving into more advanced treatment of the subject via the papers you linked to. Would be very interested in any further treatment on this blog.
Also an important paper on volatility that might be of interest here is: Forecasting Volatility in Financial Markets: A Review, Poon and Granger (2003)
@sethm: thanks for complement; in your research, do you find success with those explanatory variables; if so, curious for what types of equities?
Thanks for paper reference. Volatility forecasting is a beautiful topic; my appetite for lit survey is only tempered by its massive scope.
For equity, I have stuck to indices. Thus far I have been unable to reliably forecast volatility for individual stocks. I’ve found that the volatility of volatility of indices to be lower and thus more readily forecastable.
Thanks for the post. Happened upon it after happening upon your blog. Looking into whether these methodologies would be useful for forecasting pairwise relative returns among asset classes over longer periods, e.g, ~4 weeks, for purposes of tilting allocation levels within an overall portfolio. Just delving in now and this is a great start. Please do keep it up, your site will definitely go onto my favorites.
Hi
There has been lots of quantitative finance modeling and techniques available from books and on the net but most of them are focused on helping people to find a sell-side job in investment bank. This blog is very unique that it applies those techniques from retail investors perspective.
Thank you so much for sharing your knowledge.
I have a question regarding this formula (hope the HTML tag displays…)
I guess the sigma(t) is probably estimated by historical methods such as GARCH or EWMA or looking at the options IV, but how should the mu(t) be estimated?
I have been looking at the HSI index in Hong Kong market and most of the time the student’s T test told me the daily mean return is zero.
Thanks a lot.
Paul
oops the HTML does not show up. I mean this formula
http://s0.wp.com/latex.php?latex=r_t+%3D+%5Cmu_t+%2B+%5Csigma_t+%5Cepsilon_t+&bg=ffffff&fg=333333&s=0
Thanks
@plchung3: thanks for your kind comments.
Re HSI mu: zero daily mean return is not surprising. Use of a longer sample duration is more likely to generate non-zero mean return, whose sign will depend on market regime(s) prevailing during estimation period.
Logit estimation of mu is one approach, as mentioned above; other approaches exist (e.g. quantile estimation has shown promising results). Recall the literature has consistently demonstrated much higher accuracy in forecasting volatility (esp. conditional) than mean return (whether conditional or unconditional), hence many folks focus on volatility. Note this is the same rationale which motivates use of minimum variance portfolios.
A better reason which has attractive fundamental backing is that since the parameters are always positive they have a non constant “homogeneous probability density” (hpd). The hpd defines the distance on the parameter manifold in a theoretical modelling sense. Having constant hpd allows people to use euclidean distances metric which means the relation between priori and posterior pdfs in a data mapping sense are linear. So it is easy to interpret the influence of s change in the model to change in data. Now I order to make the hpd constant for a strictly positive parameter one must take the log of the parameter. And in the infinitesimal limit log is linear. For moreon hpds see author Jeffery I think from 1939 who first did investigation of positive parameters for inversion. Typing on phone sorry for mistakes. Josh