Index Return Decomposition
Unmasking a phenomenon 



This technique finds surprisingly often use in quant models.
Ongoing analysis and trading based on proxy hedging, exemplified by series beginning with Proxy / Cross Hedging, suggests potential for an equity decomposition model based on the relationship between returns of a stock 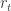
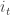
![r_t = s_t \left[ \alpha_t | z_t | + (1 - \alpha_t) \beta | i_t | \right] + \epsilon_t](https://s0.wp.com/latex.php?latex=r_t+%3D+s_t+%5Cleft%5B+%5Calpha_t+%7C+z_t+%7C+%2B+%281+-+%5Calpha_t%29+%5Cbeta+%7C+i_t+%7C+%5Cright%5D+%2B+%5Cepsilon_t+&bg=ffffff&fg=333333&s=0&c=20201002)
To explain this model, let’s build it up from intuition.
To begin, consider a trading observation: interday returns of individual stocks have a subtle relationship with their corresponding index. On some days, return for a given stock follows its index; other days, returns of stock and index diverge strongly. This distinction in behavior is commonly attributed to stock-specific “news”, interpreted broadly—whether known publicly or only privately.
This intuition can be formalized into two-state regime:
- Uninformed regime: stock return
- Informed regime: stock return
, conditionally independent of its index
Relationship between regimes can be modeled in two ways via 
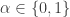
![\alpha \in [ 0, 1 ]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%5B+0%2C+1+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
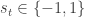
Worth noting is the following are latent variables: idiosyncratic path 
One stylized fact not explicitly accommodated by this model is well-known asymmetry of uninformed regimes, arising from analysis of market breadth: stocks uniformly go down together (think big down days), but much less often uniformly go up together (majority of rallies). Unclear whether this fact naturally arises via
Readers familiar with machine learning (ML) may recognize how to reformulate this as an additive model:
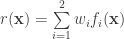
Where 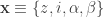
This model can be interpreted in numerous ML ways, depending on the desired objective. For example, 


Given this model, an interesting question is how to use it predicatively—whether directional or not. For example, combining models for two stocks which share a common index to introduce the notion of equity triangle arbitrage on the joint

Interesting post. I’m familiar with ML and it’s not immediately obvious why you can’t estimate/approximate the series using a variety of methods that are empirically motivated. But I haven’t read enough of your work to have a good sense of your style yet.
@Stephen: thanks for comment; to clarify my note, my sense is estimation is interesting due to two considerations: (a) lack of parsimonious way to estimate model via a single algorithm and (b) potential differing time scales per variable. Instead, the model may be best estimated by multiple steps. For example, consider starting by estimating beta using weekly data; then, estimate alpha using daily data and then backout z (at any frequency). Of course, a key estimation question is deciding which latent variables to estimate versus which to backout.
Perhaps this is what you mean by “empirical motivated methods”?
Yes, I’m jumping ahead. When you begin to use different distributions to estimate the parameters, ultra-high frequency data (UHFD) has extremely different properties, including variance and covariance, than daily, weekly, monthly, quarterly, etc. The implication I see is that the estimation process will probably not be grounded in the same event space, which will complicate the model to the point that dealing with it by selecting estimation methods through, for example, cross-validation may be more effective than trying to justify the selection of, say, a graphical model or boosting.
@Stephen: indeed; one of the more interesting questions is preferred time scale on which to conduct estimation steps. My sense is intraday is sufficient for descriptive estimation, from which interday may be interesting for predictive estimation. Perhaps a topic worth a follow-up post.
I will ping you privately to discuss in more detail.
Sorry, but I’m not really familiar with all the terminology that you’re using. Can you explain what s_t is and what ML is?
@s: s_t is the integral sign of the return at time t (i.e. 1 or -1); ML = machine learning. Updated post to clarify both.
ML = machine learning
I assumed s_t is a stock’s price at time t.
Do you have a reference for the asymmetry of uninformed regimes mentioned above? Gain/loss asymmetry is well known, but this is a stronger statement.
@gappy: when r is an index, gain / loss asymmetry is equivalent to uninformed regime asymmetry. Proof: an index is defined to be an exclusively uninformed regime, due to alpha=0 for all time t; thus, any index gain / loss asymmetry is equivalent to uninformed regime asymmetry. In contrast, evaluating uninformed regime symmetry for non-index r is a different question and minimally presupposes a methodology for z estimation.
“when r is an index, gain / loss asymmetry is equivalent to uninformed regime asymmetry.” sure, but this is a very special case. For the general case, in which asset beta is dependent on the sign (or more generally, on the distribution) of the index return, are there any references?