In R: Cross Sectional Volatility
Readers of Cross Sectional Volatility raised numerous questions on implementing the trading signal derived from cross sectional volatility. Towards exploring and visualizing these questions, an implementation in R is considered here.
Begin by assuming a frame exists named ret which contains a sequence of log returns (columns are stocks, rows are seconds), measured at second intervals, with 
N <- 5 # number of stocks T <- 50 # number of seconds in "past" H <- 60 # number of seconds in "future" k <- 4 # number of PCA eigenvectors to use
For simulation sake, suitable values drawn from a normal distribution can be constructed as:
ret <- data.frame(replicate(N, log(1 + rnorm(T + H)/100)))
Given returns in ret, construct 


X is the “past” returns over which principal components are calculated, with length T (
future are the “future” returns over which prediction is generated, with length H (
M is the average return for each stock (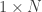
Y is the de-meaned “past” (
N <- length(ret) X <- as.matrix(ret[1:T,]) future <- ret[(T+1):(T+H),] M <- colMeans(X) Y <- scale(X, scale=FALSE)
Visualize log returns and cumulative log returns via plotting the following:
plot.ts(X)
par(mfrow=c(3,2))
for (i in c(1:N)) {
lab <- paste('X', i);
plot(cumsum(X[,i]), type='l', main=lab, ylab='', xlab='')
}
Providing charts which look like familiar medium-frequency equities:


Next, perform PCA and construct 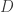


rotation, thus [,c(1:k)] selects the top-
phi <- prcomp(X)$rotation[,c(1:k)] D <- Y %*% phi
A summary on prcomp(X) reveals:
Importance of components:
PC1 PC2 PC3 PC4 PC5
Standard deviation 0.01137 0.009963 0.009274 0.008849 0.008132
Proportion of Variance 0.28177 0.216240 0.187370 0.170580 0.144040
Cumulative Proportion 0.28177 0.498010 0.685380 0.855960 1.000000
Thus, the top
Given 




B <- c()
for (i in c(1:N)) # iterate over stocks
{
hsum <- future[1,i]
Dsum <- D[T,]
for (j in c(2:H)) # generate rows by walking up the horizon
{
hsum <- rbind(hsum, sapply(data.frame(future[c(1:j),i]), sum))
Dsum <- rbind(Dsum, sapply(data.frame(D[c((T-j+1):T),]), sum))
}
B <- cbind(B, lm(hsum ~ Dsum)$coefficient[c(1:k+1)])
}
Plot hsum and Dsum for a given stock:

via:
par(mfrow=c(3,3))
plot(hsum, type='l')
for (i in c(1:k)) {
lab=paste("Dsum[",i,"]");
plot(Dsum[,i], type='l', ylab=lab)
}
And, OLS residuals for all N stocks (which exhibit serial correlation, but do look mostly stationary):

Generate accumulated estimated 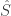

Dhat <- colSums(D[c((T-H):T),]) S <- Dhat %*% B Shat <- as.vector(S + M) R <- as.vector(colSums(future))
Where each is a vector, with one accumulated horizon estimate per stock. Inequality comparison of estimated and actual generates the trading signal:
signal <- R > Shat
cat('Shat:', Shat, "\n")
cat('R:', R, "\n")
cat(ifelse(signal==TRUE, 'SELL', 'BUY'))
With results:
Shat: 0.02340865 -0.00604718 -0.03142925 0.02960236 0.04318216
R: 0.04080749 -0.002699089 -0.05541317 0.02654577 0.04163165
Signal: SELL SELL BUY BUY BUY
Thus, signal for the current second: sell short stocks 1 and 2; buy stocks 3, 4, and 5.

Hi,
have you tried backtesting this technique on daily data and universe be e.g. S&P 500, EUR/USD, Bond ETF and Silver? I would be interested to know if it is worth implementing on not very high-frequency data, but the daily ones.
Jozef
@jozef: I have not done so, but am fairly skeptical for daily.
By universe I meant only S&P 500 index (not included stocks), thus I suggest 4 assets in my comment above.
@jozef: while admittedly not having performed the analysis, unclear whether there is economic intuition to justify strong principal components underlying such a small asset set (covariance matrix is likely to be very noisy); with the possible exception of macro factors, such as business cycle or monetary policy, which would a priori seem to have little potential for driving daily convergence.
Hi, seems reasonable, that the asset set is very heterogenous. What about stocks from the same sector, but on daily data? I was more interested to know whether this technique is feasable on daily data.
sorry, have not spotted your answer about daily data. thanks for prompt reaction. Jozef
Well, if we have buys and sells for with a random data, there is something wrong with this strategy, no?
@Breno: nothing wrong, that is intended behavior: the model generates a continuous sequence of long/short directional signals (one per second), presuming a position for every stock at all times; thus, the model is naturally suited to supply liquidity when run via limit orders.
If execution discretion is desired, the model can be overlaid with an execution confidence signal (for example, by evaluating a fitness statistic from the long-horizon regressions).
You might want to define X before calling plot.ts(X) in your code.
(Hi BN!)
@Matthew: good point; I will reorder the prose to clarify.
The code as is fails on line
Dsum <- rbind(Dsum, sapply(data.frame(D[c((T-j+1):T),]), sum))
when j=52 using your parameters because (T-j+1) <0
Yeah, it’s better to make H equal T in this example.
@Matthew: yeah, good call; the invariant (H <= T) must be satisfied for long-horizon, which I did not satisfy in my toy example. If I get time, I will update post accordingly.
Quantivity,
I’m very glad to see the increase in activity and the posts, as always, are very interesting. It’s very kind of you to post the example in R. Please keep up the great work.
Trey
@trey: thanks for your kind comments.
So many posts are very inspiring, and some “live” examples in R are quite nice way to do a bit of experimenting and research. Thanks again for covering gray areas of CSV so much.
There is small bug in the code.
Y <- X – M doesn't really produce a centered by colums matrix (you can easily check by running colMeans(Y), it would not return 0 values).
Instead, it could be possible to use something like this:
Y <- scale(X, scale=FALSE)
@Aleksey: agreed, thanks for calling that out; post updated.
Quantivity,
I appreciated your thoughtful quantitative trading book list in a previous post. Can you please recommend one portfolio analysis book that would cover several methods from simple to complex as well as address optimization?
Much Appreciated,
Jeff
@Jeff: please clarify what type of portfolio analysis?
I was looking for methods for optimizing a collection of return streams derived from multiple strategies applied to multiple markets and even across multiple asset classes. The end result of such an analysis would be optimal weights for the various return streams to arrive at a particular portfolio return/risk/volatility profile.
Many Thanks,
Jeff
FYI, in the code you guys are running regression over not centered future returns and then add means of historical returns to Shat. Probably need to add one more line to center future returns as well? Also, if we center future returns, shouldn’t we add M*H – since we sum H future returns with a mean of M?
I suppose the regression should be be run over future returns centered around the historical mean. Otherwise, you can’t know mean of the future returns without actually “looking” into the future.
@Aleksey: recall “future” is with respect to the model trading clock, which is in the past for wall clock time. So, there is no data snooping concern.
@Alexander: implementation above is consistent with the thesis, which states “ran a regression, estimated by OLS, on the future accumulated log returns with the last sum of H-period dimensionally reduced returns in the principal component space” (p. 27). Whether using centered future returns is a preferable alternative is a different question; indeed, one worth considering.
The
futurecannot be defined as centered as that would result insignalbeing miscalculated, due to centering inconsistency: inequality on centered (R) versus non-centered (S^) returns. If you want to regress centered future returns, thenhsumshould be summed over a centered future:centerfuture <- scale(future, scale=FALSE)
...
hsum <- centerfuture[1,i]
...
for (j in c(2:H))
{
hsum <- rbind(hsum, sapply(data.frame(centerfuture[c(1:j),i]), sum))
...
Finally, S^ requires inverting the centering performed on Y, and thus is appropriate to add back the mean H (as opposed to M*H). See the bottom of page 28 in the thesis for further explanation.
There is no any assumptions about distribution of returns and all this mdoel does – trying to predict. Hence, if instead of ret <- data.frame(replicate(N, log(1 + rnorm(T + H)/100))) I put ret print(Shat)
[1] 90.98732 90.88485 90.87899 90.98547 90.87325
> print(R)
[1] 120.0778 119.9253 119.9823 120.0589 119.9198
Now, if we only do centering of future returns we get:
> print(Shat)
[1] 2.973299 2.997521 2.996584 2.976858 2.957039
> print(R)
[1] 120.0274 120.0547 120.0358 120.0382 120.0044
Now, if we add H*M instead of M in the end we get:
> print(Shat)
[1] 120.0223 119.8222 120.0676 120.1109 119.9371
> print(R)
[1] 119.9645 119.8452 120.0216 120.0628 119.9399
Last result seems the best to me…
in the above post some text didnt fit: I put ret <- data.frame(replicate(N, 3.0+log(1 + rnorm(T + H)/100))) instead of current code.
@Alexander: can you clarify what fitness metric you are using to assess “best”?
Also, can you elaborate on rationale for use of “3.0 + log(…)” for returns generation?
issue I am trying to point out here is that something is wrong with the prediction model. It happens when returns have non zero means. I bump returns high enough so the issue can be clearly seen, hence 3.0+log.
Better means smaller prediction error produced.
Alexander – no, I don’t think adding H*M is correct. You can actually “debug” the prediction model very easily, that’s how I did that:
define about 5 linear functions, like y(x) = a + kx, where for every function you have different a and k coefficients.
Then compute log differences, separate into three intervals and feed that as an input into this program.
Because these functions are linear, PCA will find one main component, and OLS will estimate necessary coefficients matrix B to “restore” future values of the function. Then by comparing computed output and real value you can see if there is any problem with the prediction model.
For one time series, did you do that?:
x – norm(0,1)
y=a+k*x — simulate y N times
Feed log(y_t)-log(y_{t-1}) as returns?
If the above comment directed at me, then:
no, I wasn’t using any random distribution, but just created a linear price timeseries, each having a different offset and slope.
This way I assured that model must predict the price correctly, it’s the easiest case scenario.
So, I calculated X as indeed log(y_t)-log(y_{t-1}), then demeaned and stored in Y, etc,etc. This is a nice test for the model. I tested it in my C# implementation, so found a few rough edges. But as for the H*M, I can assure you that it is not correct to add that as you stated. If I do that, I don’t get a correct result at all.
I may be late to the party with this thread, but I’m having trouble understanding the loop where the regression is run. Hsum seems to be correct; it is the cumulative sum starting from the BEGINNING of the H-period future return data set. However, Dsum seems to be the cumulative sum of the T-period dimensionally reduced returns but it starts at the END of the data set and accumulates the returns to the beginning. The result of regressing cumulativeSum(hsum(1:end)) on cumulativeSum(Dsum(end:1)) is a lot different from regressing cumulativeSum(hsum(1:end)) on cumulativeSum(Dsum(1:end)). Could someone please clarify?