Cross Sectional Volatility
Delay Embedding as Regime Signal prompted enough questions to warrant further commentary on the principal component space 
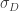
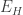
- Lineage: this model is stylistically representative of the statarb tradition, spanning from Computational Methodology for Modeling the Dynamics of Statistical Arbitrage (Burgess, 1999) to Statistical Arbitrage in the US Equities Market (Avellaneda and Lee, 2008); on the practical side, both Burgess and Neil Yelsey (acknowledged by Infantino and Itzhaki) are reputed to have run arbitrage desks
- Exemplary: this illustrates how to build models which are transformations of returns (commonly via dimensional reduction), rather than returns themselves—as Paul Grimoldi commented; this also speaks to Jeff’s question last year regarding the contrast of classic technical analysis with quantitative methods: visual pattern analysis of returns versus statistical analysis / ML on transformed returns
Intuition of this model is compelling, albeit obfuscated fairly heavily by its rough mathematical presentation: mean-reverting convergence can be predicted via a dimensionally-reduced (principal components) space of returns from an equity portfolio. The following seeks to explain this intuition, including use of more standard mathematical language than found in § 2.4 and § 3.1.
- Dimensional Reduction
First step is to choose a dimensional reduction to denoise the returns, providing a transformed basis for predicting returns. Doing so is justified by the assumption that “main risk factors should drive the stock’s returns in a systematic way, and the residuals as the noise to get rid” (p. 30), thus echoing CAPM in that return is justified by risk (yet another wonder of residuals).
The trick is identifying anonymous equity risk factors, and using them to guide denoising and feature extraction. Principal component analysis (PCA) is a natural choice, as principal components are chosen to maximize variance and thus naturally capture “risk” in the realized sense. PCA is further compelling as the corresponding eigenspace defines a principal component space which naturally serves as a feature vector for statistic / ML analysis.
Denoising occurs by choosing a small number of the dominant PCA eigenvectors and composing them into the matrix 
- Prediction
Second step is to define prediction via the dimensionally-reduced principal component space:

where 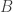

Use of a long-horizon regression to generate 
Instead, 
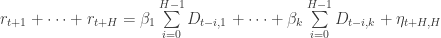
In other words, predict future returns based upon the past. Yet, the past is defined by principal components plus a noise term. One way to better understand this is to consider when 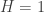
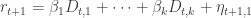
Thus, the one-step ahead return is equal to 
In this interpretation, extending the eigenportfolio longitudinally introduces the advantage of being able to observe the noise 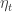



- Trade Signal
The trade signal is generated by assuming mean-reverting convergence of the residuals 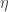
![\eta = [ r_{t+1} + \cdots + r_{t + H} ] - [ \beta_1 \sum\limits_{i = 0}^{H-1} D_{t - i, 1} + \cdots + \beta_k \sum\limits_{i = 0}^{H-1} D_{t - i, k} ]](https://s0.wp.com/latex.php?latex=%5Ceta++%3D+%5B+r_%7Bt%2B1%7D+%2B+%5Ccdots+%2B+r_%7Bt+%2B+H%7D+%5D+-+%5B+%5Cbeta_1+%5Csum%5Climits_%7Bi+%3D+0%7D%5E%7BH-1%7D+D_%7Bt+-+i%2C+1%7D+%2B+%5Ccdots+%2B+%5Cbeta_k+%5Csum%5Climits_%7Bi+%3D+0%7D%5E%7BH-1%7D+D_%7Bt+-+i%2C+k%7D+%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
This convergence arises by construction from least squares regression estimation of the
Or, in trading speak: if actual returns are larger than predicted returns, then assume the corresponding stock is overvalued and sell; otherwise, buy.
- Cross Sectional Volatility
Finally, a cross sectional volatility metric 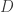
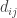

where the cross sectional mean is defined in the standard way:

Hence, coming full circle:

There is an unclear area in their thesis, maybe it is unclear only to me, but:
1. T seconds period is introduced (p.26). This is a fundamental thing, yet not explained. Is it a trading period, a sliding window for analysis.
2. H seconds period is introduced (p.28). Another very important variable, probably a prediction horizon.
3. Actual mean-revert model (p.28), without regime switch. Let’s consider this. We are at time t: There is a historic period (having length of T periods?) for which PCA is calculated, eigenvector is found. In order to find B, it’s needed to perform OLS regression on future returns (the length would be? H periods?). So, to run it without “looking in the future”, at the time moment t, we need to start analyzes at t-T-H, then perform regression on (t-H, t), and only then take trading decisions.
Is that the correct way, or am I misunderstanding something?
Maybe that’s why you made a note about 2H period in your post
You are correct, prose and mathematical clarity are incomplete.
There is a fundamental, yet unformalized, “sleight of hand” going on which I believe is a key root cause for confusion: the model is presented as being tradable online (i.e. in real-time), although the model and its use in back testing is off-line (i.e. evaluated over fixed dataset). This leads to prose confusion, as well as mathematical conflation. For example, the long-horizon regression literature is classically off-line, and thus is not interactively time-parameterized. Given no trading clock is defined, no formal machinery exists to help clarify this ambiguity.
This problem bleeds through: use of time parameterization in the matrix algebra is inconsistent in § 2.4: S is not S(T); M is M(T) on p.29, but not time-parameterized on p. 26. Thus, both “now” and “future” represent points in time by a model trading clock which is not equal to standard wall clock (i.e. “now” is not the current time; and “future” is in past of standard clock). Note that “now”, in the model trading clock, is represented by t.
So, given that preface, here is an interpretation of the variables, trying to bridge gap between offline and online:
1. T is the number of seconds, measured in the model trading clock, of sequential returns measured backwards from “now”. In other words, this is the “past” for PCA.
Unfortunately, this leads to yet more confusion: if “log returns” are being measured in ticks, then the dimensionality of X is wrong: dimensionality should be number of ticks, not number of seconds T (unless there is exactly one tick per second for every second, which is ridiculous). In contrast, if “log returns” are measured in seconds, then they are clearly not the sequence of tick-by-tick returns implied in § 2.1. Worse, use of a temporal trading clock results in a model whose sampling estimation varies on tick frequency: periods of high tick frequency will result in lower “sampling”, in comparison with periods of lower tick frequency. Unless they are not sampled, but instead accumulated; but, that introduces more confusion.
2. H is the number of seconds measured in the model trading clock, of sequential returns measured forward in wall time from “now” (i.e. in the “future”, according to model trading clock). In other words, now as measured in the standard wall clock is (t + H). Note, the same problem as with T arises regarding tick frequency: sampling tick frequency will determine the values for r.
3. Correct. Use of a model trading clock helps untangle this: “now” is t, which represents current wall clock minus H seconds; given “now”, PCA is calculated from the past T seconds of returns. Given “now”, prediction is calculated from the future H seconds of returns. Thus, the relevant return series measured in the model trading clock are [t – T, t + H]. The relevant return series measured in standard wall clock are thus [now – T – H, now], given the H offset from model clock to wall clock.
Note that reference to 2H is unintentionally sloppy, as it presumes H = T. I will add a clarifying comment to indicate the longitudinal stationary period must be (H + T).
Is there any reason to necessarily not overlap periods T and H? Instead of viewing this as [now-T-H,now], simply [now-T,now] where T=H. Is overlapping the period on which you calculate the OLS regression and decompose the PCA eigenvectors particularly unsound? Aren’t you doing this anyways by defining t as T-H?
@Steph: good question–not one I previously considered.
Thinking via reverse induction, consider the extreme limiting case of overlap (i.e. T and H are fully overlapping); in this case, the “past” and “future” are the same and the long-horizon prediction should be “perfectly predictive”. In this case, it would seem the residuals are degenerate and thus have little “signal”. Given that, seems both dimensional reduction and regression would be independently sound in the strict statistical sense–but when combined would not generate useful signal. Following induction, seems more limited overlap would suffer from the same problem with smaller magnitude of effect.
I think my confusion is over exactly which period you’re regressing over the dimennsionally reduced returns. For example, in your R code:
..
for (j in c(2:H)) # generate rows by walking up the horizon
{
hsum <- rbind(hsum, sapply(data.frame(future[c(1:j),i]), sum))
Dsum <- rbind(Dsum, sapply(data.frame(D[c((T-j+1):T),]), sum))
}
B <- cbind(B, lm(hsum ~ Dsum)$coefficient[c(1:k+1)])
}
..
From time t, the intersection of T and H here, (Call it row 50 if you like), you're walking forward and calculating the cumulative return and simultaneously walking backward to calculate the the cumulative return over the dimensionally reduced space. But when j=H (Again say 50), you're comparing the cumulative future returns from 51:100 vs the dimensionally reduced space back at 1:50.
The paper is somewhat cryptic and simply specifies that "the future accumulated log returns with the sum of the H-period dimensionally reduced returns" by which I had though the intent was to calculate the backward looking principal component analysis as we take each step forward.
@Steph: here is ASCII art illustrating timeline: |—- T —-|—–H—-|now, where “now” represents the current time as measured in wall clock calendar.
In prose, walking backwards from now: the H periods preceding now are used for long-horizon regression; the T periods preceding H are used for dimensional reduction. In total, (T+H) periods previous to now are considered for the entire model.
There also is an uncertainity about calculating H-period future accumulated return.
For example, for period H accumulated return is r(t+1)+…+r(t+H) the past returns are summed in time from t to t-H (page 28). But it’s not obvious from their work that r(t+1) uses just Dt . You specifically clarified this in your post (that it just uses Dt), but I’m not sure whether this is correct. If we look to page 29, they define a matrix D^, which contains previous accumulated returns for the defined period H for all every t out of T interval.
@Aleksey: am I correct that you are referring to the following definition (for D^): “accumulated historical H-period dimensionally-reduced returns given in D” (p. 29). Agree this is the summation over D (sliding over a window of length H), so is consistent for multiplication with estimated betas; indeed, D^ (p. 29) is the summed D in long-horizon (p. 28). Yet, this further conflates T and H: D (and thus D^) is parameterized over t: [1,T] (past), while being summed over [0, H – 1] (future).
Sorry, I didn’t mean your interpretation is incorrect, but it sounded like I said that. I digged more into the formulas, they are quite obvious really, but I still have one concern. I will refer to your topic, it’s easier. So let’s define three one-step future returns as these:
r(t+1) = b1 * Dt,1 + … bk * Dt,k + residual.
r(t+2) = b1 * Dt+1,1 + … bk * Dt+1,k + residual.
r(t+3) = b1 * Dt+2,1 + … bk * Dt+2,k + residual.
Is that correct? If yes, then accumulated return would be
r(t+1)+r(t+2)+r(t+3) = b1 * SUM(Dt+i,1) + .. + bk * SUM(Dt+i,k) + residual. Where i goes from 0 to 2.
Now what I misunderstand is why in the formula at the bottom of p.28 (it would really help if authors numbered the formulas!) has Dt sums going as Dt-i. Why minus?
In fact (I decided to put that as a separate comment), I think I am expecting something way more complex than what’s explained in the paper.
I was thinking that they are describing a way to define some kind of a “hyperplane” inside the future trading period H, which would mean predicting accumulated returns at each moment of time [t+1, t+H), and hence trading the mean-reversion or momentum according to the cross-validation inside this interval. At least, that’s what seemed natural to me. Am I wrong and they just define the future accumulated return by the end of the prediction horizon?
I believe the sums in the model’s equation at the bottom of page 28 should not extend up to H in the past. They should end when i = H-1.
You said “while being summed over [0, H – 1] (future)”. Was that related?
@Aleksey: subtraction is due to walking backwards in time from “now” (which is t, in model trading clock), as Dt is defined over the “past” and addition is symmetric.
Not sure I understand your second comment: what additional complexity are you expecting? I believe future accumulated return (T) and prediction horizon (H) are defined to be contiguous in the model trading clock, with t (“now”) being the delineation point.
@Jules: long-horizon does not strictly require so. Difficult to say definitively from the thesis, given methodology of the long-horizon in prose and formula are in conflict. That said, my interpretation is affirmative: intent for summation in both dependent and independent is equal length (i.e. [0, H – 1]). I will update the post accordingly, so at least it’s consistent here (albeit then inconsistent with the thesis).
Hi. Nice writeup. Have you tried it? PCA as a means of determining cross-sectional factors of course makes sense.
I’m a little skeptical about their execution assumptions though. I’ve seen many “profitable” medium – HF strategies that made some critical assumption re: execution and essentially are accumulating the bid-ask spread or some fraction thereof at high freq, showing phenomenal returns.
If their prediction is generally good for periods of a few minutes then is probably workable. They do indicate periods as small as a second (which I think is not reasonably executable in and out).
@Jonathan: thanks for your kind comment. I strongly concur with your skepticism over execution assumptions, not to mention the above concerns with trading clock. One author acknowledges all the following unaddressed concerns: competition, transaction costs, slippage, and market impact. Given those concerns, certainly some work is required to adapt it for live trading (which I have not done).
It seems to me that for the matrix S to be (1xN) the matrix of coefficients B defined page 29 should be (Nxk) instead of (kxN). Am I mistaking?
Thanks
Jules
Hi,
This is probably a stupid question, but in Infantino and Itzhaki’s paper how do they calculate their “Cumulative Log Return” for the strategy which they kind of use in place of trading simulation PnL? I understand that every second they either buy or sell each of their 50 stocks, and then what? Thank you.